The digital world is undergoing a major revolution: Machine Learning or ML (a subset of Artificial Intelligence or AI) is being used increasingly in our digital world. There are many applications such as for image recognition or voice recognition, meaning the AI model is interpreting or ingesting information and providing an attempted description of that content. This allows people access to subtitles (for the hearing-impaired) or makes it easier to track down that photo in your library you just can’t find.
What happens though when these interpretations are turned around into advice, to direction, to action? In particular, recent advancements in Generative AI and Large Language Models (LLMs) are pushing traditional search engines to reconsider what’s possible. Google have led the Search Engine business for decades with more than 90% of global search volume representing a monopolistic market dominance in that space. Hence when Google announces changes to their search engine, the technology world pays very close attention.
A few weeks ago Google announced at their annual conference that they were intending to gradually introduce Generative AI search results based on their Gemini AI, to their standard web search engine, calling it AI Overviews and launching it in the USA initially, with other countries to follow in coming months.
In a move similar to the iconic “I’m feeling lucky” button, that will take you straight to the top search result answer rather than letting you read and select the one that fits best yourself, AI Overviews will present its response to your question with no links to external sites required to be followed, should you wish to just trust its response.

Of course you can follow links further down the page to clarify the answer, but to those that genuinely aren’t interested in digging for themselves, it’s easy to simply take the response on face value.
People are going to be people, and if something like AI Overviews exists people are going to poke it, and poke it, and poke it, until it breaks. It didn’t take long either. Examples began cropping up on social media of search examples that suggested adding Glue to Pizza Cheese to stop it sliding off the pizza, mixing Bleach and Vinegar to clean a washing machine (that would make Chlorine Gas…see below…), and that eating a rock a day might keep the doctor away. There are many, many more examples but that’s a small sample.
To a human, two out of three of these examples above are obviously ridiculous, however the Chlorine Gas example is not necessarily so obvious for those not familiar with chemistry. Whilst I personally know that the active ingredient in bleach is Sodium Hypochlorite (NaClO), Vinegar is Acetic Acid (C2H4O2) and if you mix Hypo with an Acid it will liberate the Chlorine Gas in that chemical reaction. Many people don’t know this. It may sound reasonable to some people and they may attempt it without a second thought with potentially deadly consequences if this is done in an enclosed space, with little to no ventilation.
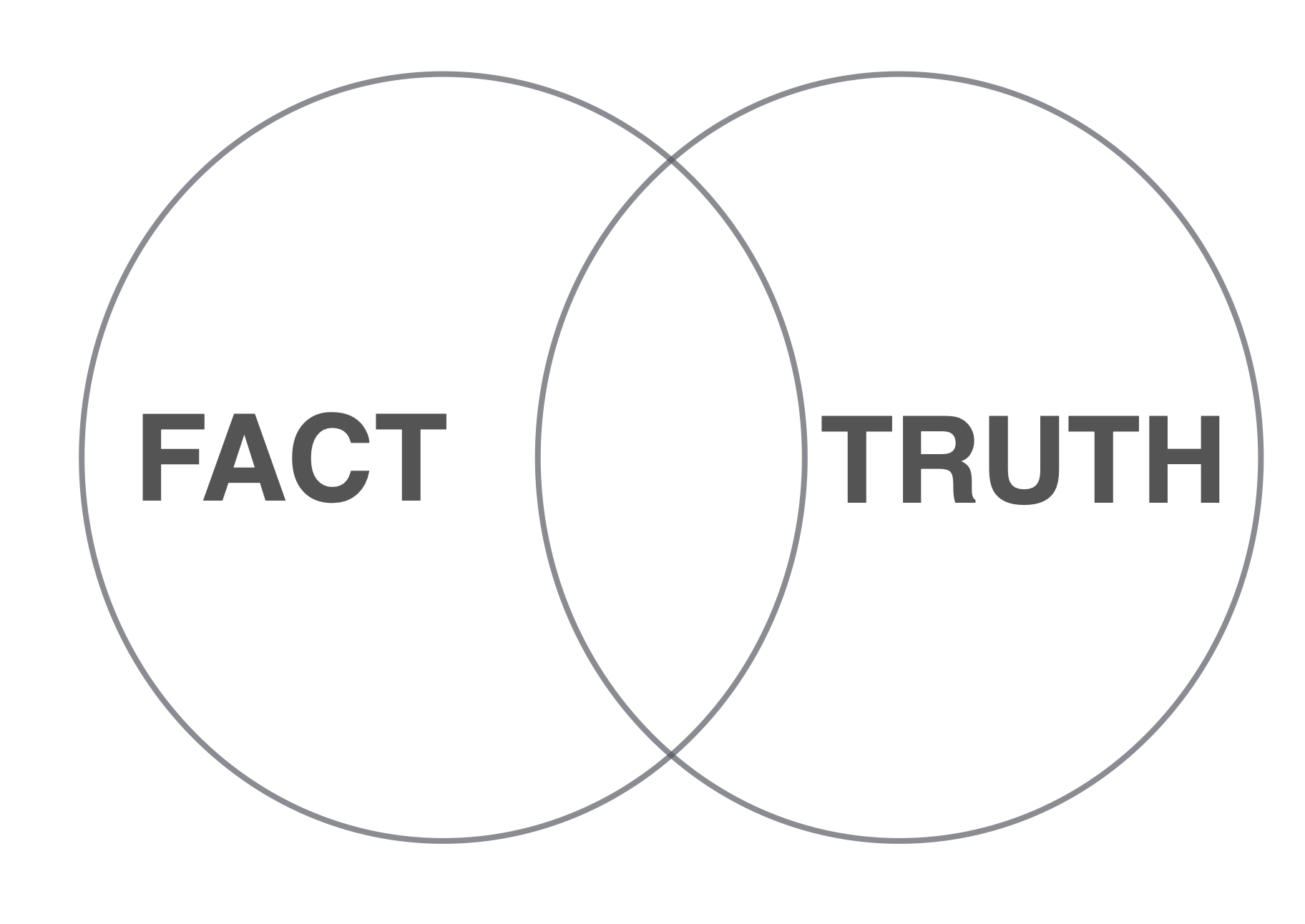
The problem is that ML of this kind is attempting to provide Facts, but in reality it can only ever realistically, provide Truths. To understand what I mean, we need to refresh ourselves on the differences between these two things. The dictionary definitions of each offer some help in differentiating Truth vs Fact, with the following extracted from the Oxford Dictionary’s attempt:
- Truth: the quality or state of being based on fact; a fact that is believed by most people to be true.
- Fact: a thing that is known to be true, especially when it can be proved.
To paraphrase then, “Facts” are things that can be proven and “Truths” are things that are based on the majority belief (opinion) that may or may not be provable. Hence in a Venn diagram Truths can contains Facts, but there are Facts that may not be believed by the majority and are thus not considered to be Truths. The ideal position is the overlap point where Facts are believed by the majority and are also therefore considered to be Truths. The size of this overlap is highly variable and flexible over time depending upon the topic in question.
That’s nice, you say, so what’s the big deal? Well…all ML models are only as good as their input or training data. The old adage of “Garbage in…garbage out” applies. Ensuring the quality of input data has been an age-old problem that highly trusted publications like the Encyclopaedia Britannica have been grappling with since its inception in 1798. In many way EB was the worlds first large-scale attempt to capture factually provable information on a broad range of topics.
They relied on researchers interviewing and investigating their entries and cross-checking wherever possible with significant emphasis on information from credible sources. Whilst Wikipedia can be useful for quickly tracking down high-level information on many topics, its collaborative model allows for rapid changes that aren’t necessarily referenced (citation needed) which creates a maintenance burden for those wishing to have content corrected.
Real-life subject matter experts and even those directly discussed in Wikipedia articles find themselves unable to have errors corrected. The rate at which un-cited or factually incorrect information can be added, far exceeds the rate at which Subject Matter Experts can rectify it, due to its open nature. Unlike EB (as an example) that has an Editorial bottleneck to prevent incorrect information from easily entering, Wikipedia does not have this. As such most scholarly organisations do not permit linking to Wikipedia, whereas linking to EB or more controlled information sources, is generally more accepted.
The only potentially sensible path to take is the flagging of input content into AI models that has Meta-data that identifies its quality, factuality, or trustworthiness. How one determines this score or criteria is highly subjective and prone to influence from human biases that mutate over time, can be based on current micro/macro societal trends and such, but assuming this is even possible could you encode information with a watermark or traceable identifier that it came from a human? A factually accurate source?
Irrespective of the technical solution for how this could be accomplished, the far better question is, what is the incentive for content creators to add such meta-data legitimately and then what is the punishment for not, or for mis-encoding it, assuming the difference can be reliably detected? Just because data was created and entered by a human doesn’t mean it’s accurate, factual or even sensible. It could be gas-lighting, trolling, a mis-understanding or basic ignorance. If one was running a spamming server-farm operation designed to pollute the world with mis-information for a price to the highest bidder, then why would/should they flag their data correctly?
Wikipedia is however a balance and counterbalance system such that, if we add disruptive information, there is an opportunity to correct the imbalance..albeit potentially slowly. Too many people take Wikipedia on face value as fact, when it is closer to a Truth than to a Fact in many cases. What happens when people start to take Google Search’s AI Overviews as Fact, rather than as a Truth? Individuals are not so freely able to provide feedback input as they are for Wikipedia and if they do, can it be trusted?
Let’s say that a human makes a website, YouTube or TikTok video with information that was guided by Generative AI content, which then is re-ingested by the AI model. Over time this then adds reinforced incorrect information into the AI model which then further provides incorrect responses for still others to potentially believe.
This pattern is no different to existing Human conditions, sometimes referred to as Urban Legends, or more traditionally the term used was folklore.
Before the internet, small groups of people could believe a Truth without external validation. This is as true today as it was thousands of years ago. Even for insular online communities, this is still prevalent today. This is in many ways, nothing new.
We have turned to the Internet and technology to create a body of knowledge that is unsurpassed in all of human history for people to turn to, for answers to questions ranging from the trivial to the life-threatening. However with AI now able to amplify factually incorrect information at a more rapid pace than ever before and many people seemingly willing to believe what it says, will these tools just become the ultimate Random, Unintentional Gas-Lighting mechanism for factually incorrect information in our history?
There is so much buzz surrounding the use of ML in this way and yet no matter how I look at it, I can’t see how this is a solvable problem. On an individual level it will come back to trust, and it’s hard to look into a future where people simply start trusting, blindly, what the ML spits out.
Perhaps we should return to word of mouth? Return to trusting professionals that have studied and practiced for decades in fields of construction, telecommunications, plumbing, electrical wiring, laying bricks, making pizza even, and anything else for that matter, rather than asking a search engine or watching a YouTube video looking for a quick and easy answer to a question.
Maybe it’s better to return to reading up on materials from multiple sources, books, papers, talking to people and making up our own minds rather than leaning on automated systems to do the thinking for us in hope of saving a few minutes. There is no substitute for taking the time, making the effort, educating yourself and thinking it through. There never will be either.
Some decisions you need to seek the right answers and to ask the right people, and stop pretending the internet can give you the right answer for everything, every time. It can’t now, it never could, and it never will.
Treat AI responses the same way you treat a door to door salesperson: with a large dose of skepticism and some weary caution.
There are many applications where AI/ML can be beneficial to humankind. This though, just isn’t one of them.