Herein you’ll find articles on a very wide variety of topics about technology in the consumer space (mostly) and items of personal interest to me. I have also participated in and created several podcasts most notably Pragmatic and Causality and all of my podcasts can be found at The Engineered Network.
TD Shirts
To celebrate the 50th episode of Causality on (my podcasting site) TEN we’re releasing a range of Tee-shirts and smartphone cases by Cotton Bureau! Which can only mean that the TEN Store is once again open!!
I’ve released the first ever, TechDistortion Tee-Shirt for the true die-hard fans of this blog! It will remain open with items on sale only for a limited time, so grab something you like…while you can!
All Patreon supporters on TEN have access to a special discount off their purchase, should they wish to: for details Patrons should check the TEN Patreon page.
All Tee-shirts are by Cotton Bureau and you can choose from a Tee-Shirt (Standard or Heavyweight), Sweatshirt, Tank-top or a Onesie (for infants!), fitting for Men, Women, Youth or Toddlers too. With a choice of fabrics from Natural Tri-Blend, Black 100% Cotton or a Navy Blue 100% Cotton all in a wide range of sizes.
The Original Tech Distortion Shirt: Without Distortion



Letter To Tesla Part One
Being a very happy (for the most part) Tesla Model 3 owner for over 9 months now, and with 22k on the clock I’ve finally decided it’s time to write down some areas for improvement for this amazing vehicle. These aren’t physical change suggestions or anything complicated and I have four to suggest.
I could point out things like better water resistance of the electric window components (mine have developed a squeak on raise/lower whereas my Honda Jazz is going over 8 years without a single squeak ever from any of its electric windows) or a non-bluetooth auto-unlock proximity sensor (long story) instead I’m going to focus initially on things that are simple software tweaks.
I’m certain that Tesla get a lot of these requests and I’m also sure that Elon Musk is a busy man (okay I know he is) so these many not find their way to implementation in the short term but I’ll settle for a feature that’s on a backlog list somewhere for a future update - even if it’s a few years down the road.
None of these are Rocket Science Mr Musk sir, that’s the other company you also run…where it really, actually is…
FM Radio: Add a Seek Function
When you’re in range of cellular data (so far as I can tell) another option appears called “Stations” which is a list of FM stations that the Tesla believes it can find or that should be there based on your location. But if that’s not there, you can direct tune if you know the exact frequency you’re looking for. However under “Direct Tune” there is no way to ‘Seek’ for an FM Station as the current screen looks today:
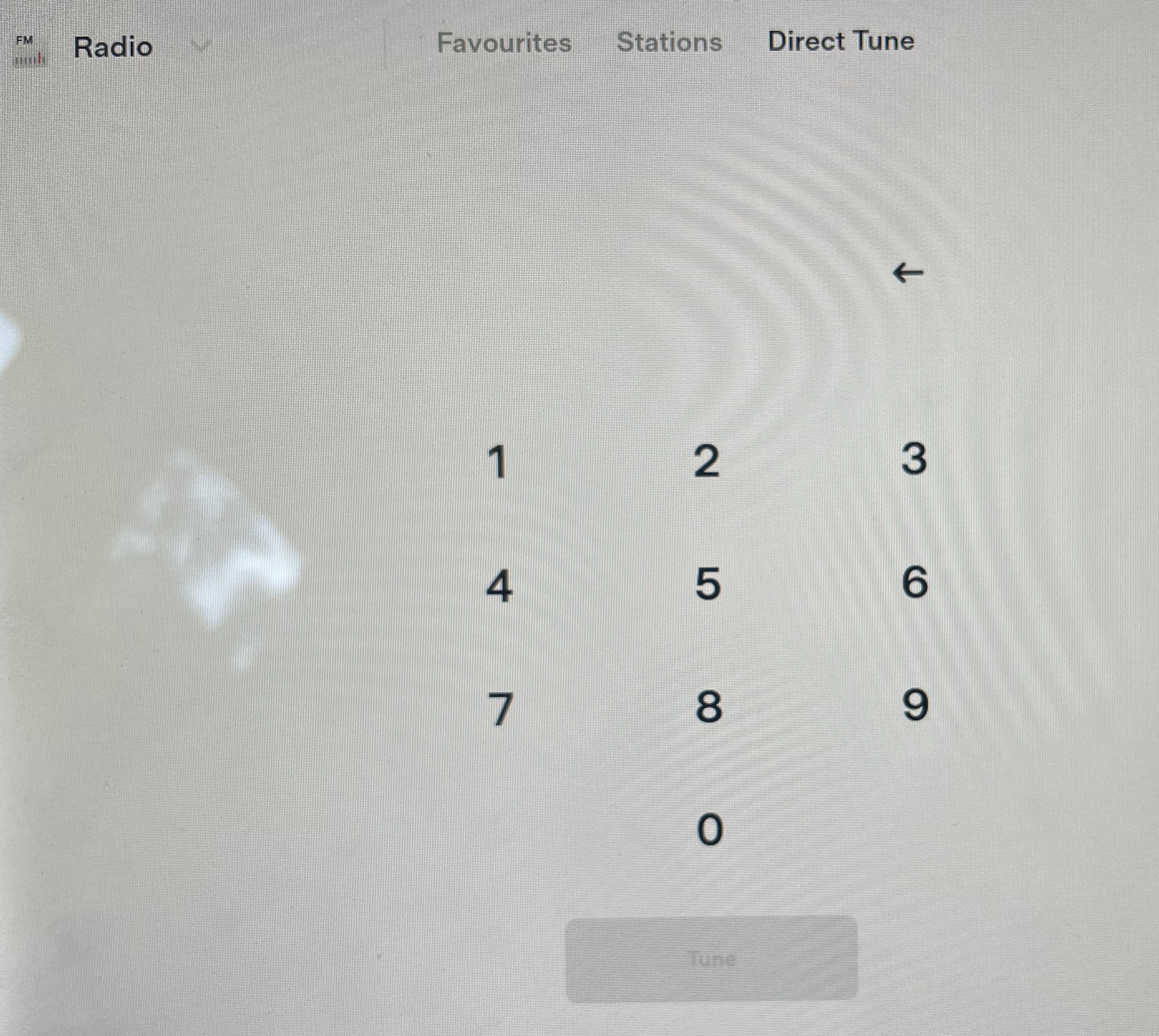
In my experience on roads only a few hours inland from Brisbane, direct entry found listenable stations on FM (minimal fade and chop) and yet they didn’t show up in a Stations List. A very simple set of seek buttons like every other digital FM Radio I’ve ever used has, would be very helpful.
REQUEST: Add a “Seek +” and a “Seek -” button on the Direct Tune FM Radio screen.
Air-Conditioning Slide-up View Without Starting the A/C
In V11 user interface, when you want to adjust the details of the Air-Conditioning, you need to tap the temperature which slides up the panel. If the A/C is currently off, this single tap automatically turns on the A/C, which more often than not is NOT what I need to do. I just want to confirm if the Recycle is open to vent for example, or to adjust the set heaters in the rear.
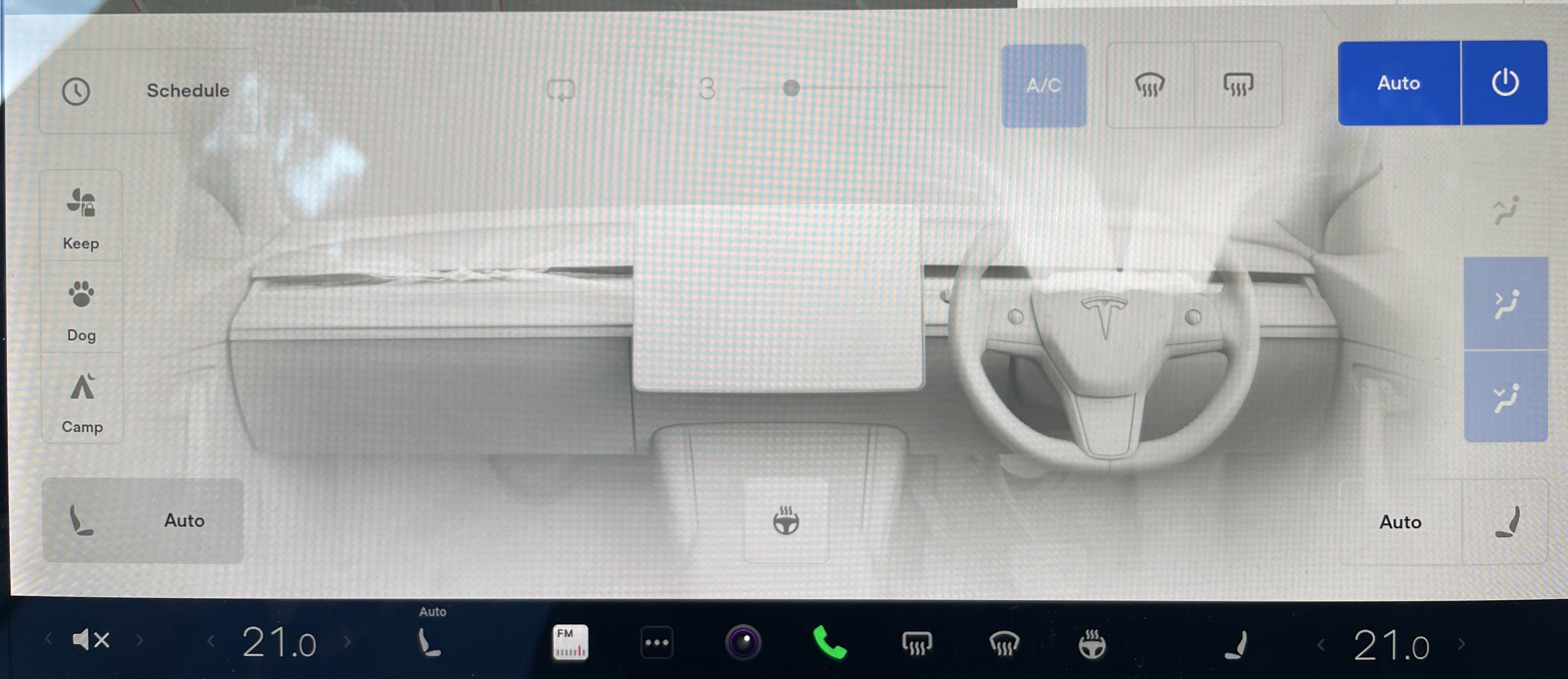
Pressing and holding the temperature will toggle the A/C on or off without raising the panel. Tesla added some short-cuts to the menu bar to adjust the front seat heaters and the steering wheel heater but there are still plenty of other useful functions that are contained within the main slide-up view. If the A/C is currently off it’s because I turned it off and want it to stay off.
REQUEST: Change a tap to the temperature to slide up the panel only, irrespective of whether the A/C is running or not.
Mirror Dimming: Add Manual Enable/Disable
The (re)addition of dimmable mirrors in mid-2020 was welcomed by Tesla drivers however there’s only one option in the menu system to enable “Auto Dim” mirrors. If enabled, the side mirrors as well as the interior rear-view mirror will dim provided the car is in Drive, the angle of the sun is 5 degrees below the horizon and the headlights are turned on.
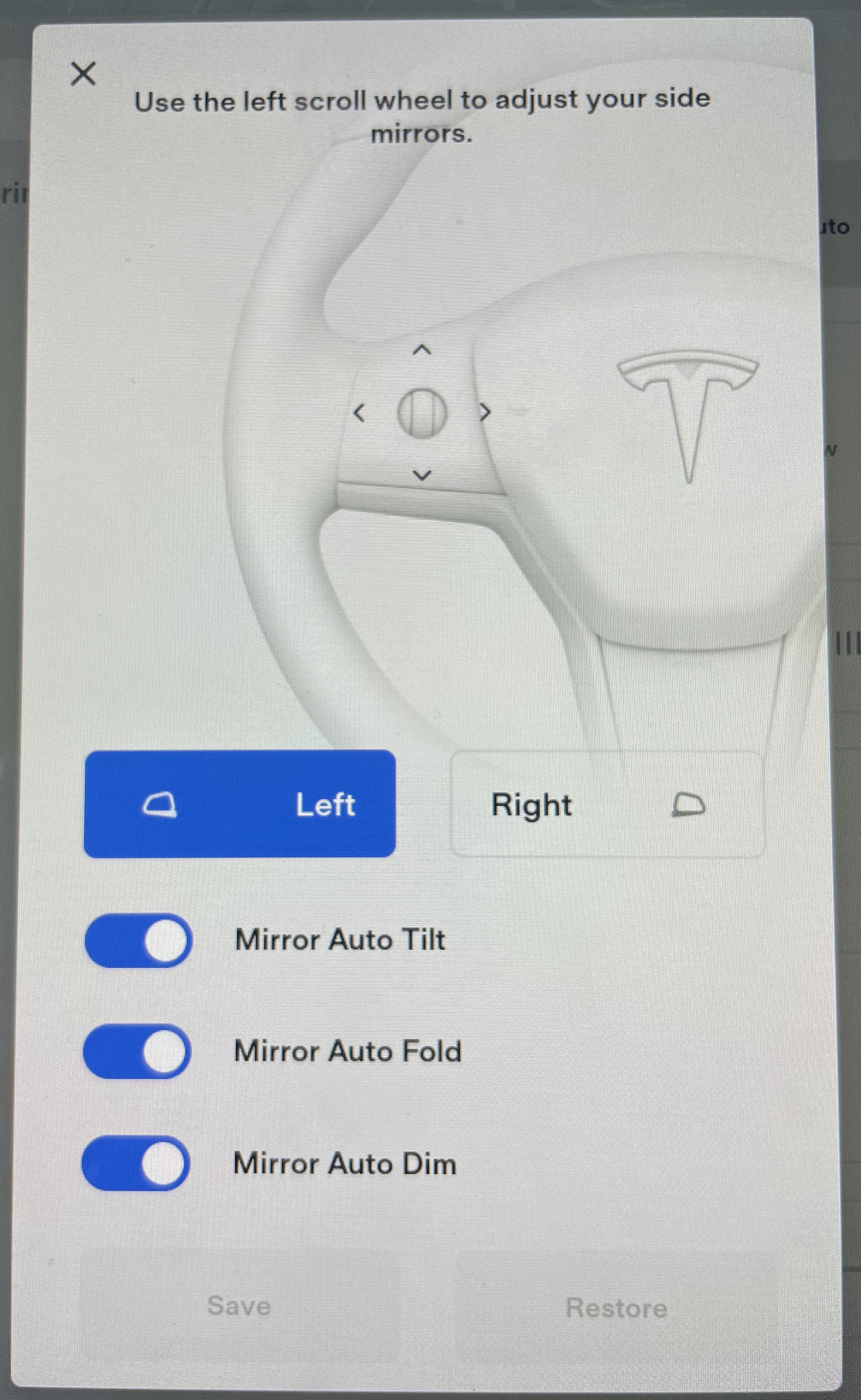
The problem with this is that many drivers turn on their lights before sunset and with its low ride height the Model 3 gets plenty of larger 4WDs blaring into your eyes 30 minutes or more before the Tesla logic will permit the dimming. In every other car I’ve ever owned, if I needed to dim the mirror I’d flip the metal/plastic toggle on the rearview mirror and instant dimming would occur.
REQUEST: Add a toggle button to turn the Dimming On and Off that’s quickly accessible.
Predictive Speed Reduction in AutoPilot
When in full AutoPilot, the Tesla attempts to read the speed sign and when the Tesla passes in-line with that sign, it will automatically adjust the speed limit up (if it was set higher as it’s Max set-speed previously in the drive) or it will adjust the speed limit down accordingly.
Going up is fine, but going down isn’t, since it only drops your speed once you’ve passed the sign meaning that until the cruise-control lag slows the car down you’ve been speeding for a hundred meters or so after the speed limit dropped when you’re dropping from 100 to 80 kph for example.
The fix is simple using Newtons second law of motion. You have depth perception (and a GPS too) in a Tesla so you could calculate the distance between the current position and the upcoming speed sign change position, so figure out based on the deceleration curve when to start slowing down so you reach the speed limit when you actually pass the sign.
In Australia the police will intentionally set up speed traps in those spots trying to catch drivers out…it’s a speeding ticket waiting to happen.
REQUEST: Add a toggle in Autopilot for “Predictive Speed Reduction”
Other Articles
For reference I’ve written a lot of articles about my Model 3 in the past 9 months.
I’m sure there’s more, but that’s enough for now.
Leaving Fast Chargers Behind
This weekend gone I was invited to visit an extended family member’s Pub in Monto. For my wife and I it was a bit of an adventure - somewhere neither of us had been before and for me, staying a few nights in a country pub was something I hadn’t done for over 25 years.
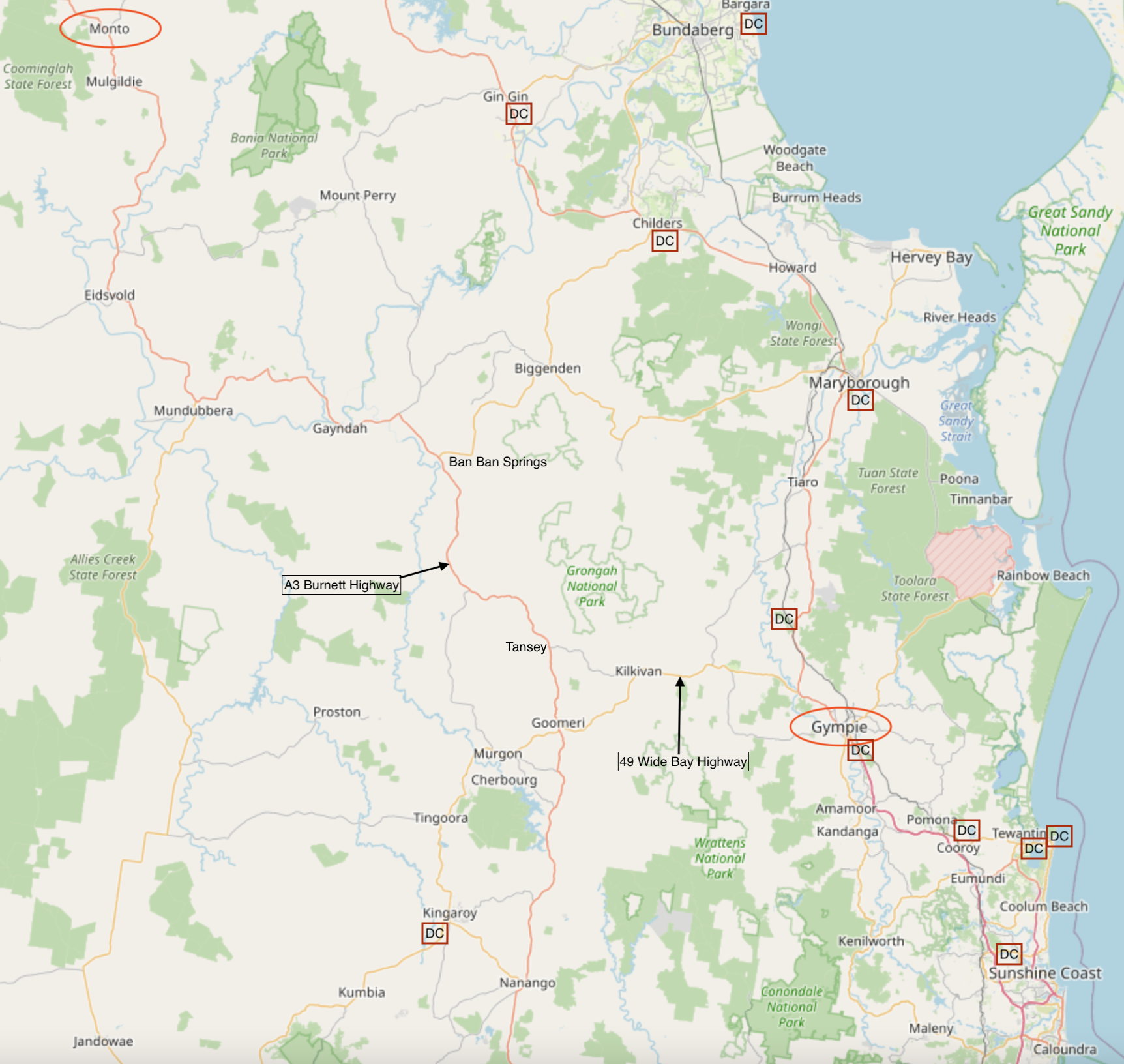
Monto is located off the main highways in Queensland and yet, I wanted to take the Tesla and see how it handled the long road trip. Monto is about 5 hours drive from my home about 400k’s (250 miles) one way. The shortest route takes the Bruce Highway North to Gympie where there are two DC Fast Charging locations and then the route turns inland via Kilkivan via the Wide Bay Highway, then a short-cut to Tansey, then to Eidsvold and eventually Monto via the Burnett Highway. After Gympie there are no charging points at all. None. No DC Chargers, CCS-2 Combo or CHaDeMo connections, no AC outlets meaning no 3-Phase outlets, no Type 2 or even Type 1 charging points. You’re down to a standard 10A household outlet or if you’re lucky a 15A outlet.
There are two short-cuts between the Burnett Highway and the Bruce Highway where all the DC Fast Chargers are: via Kalpower which is effectively a dirt road and via Mount Perry, though the two roads via Mount Perry, the nearer to Monto is closed for roadworks until 2023 and the other joins so far South it’s effectively doubling-back for no net gain. So you can forget a quick charge or any charge - you’re on your own.
Destination Charging
The Pub owners were happy to let me park and charge Tessie around the side near their 24-hour Laundromat and I initially plugged in a 10A lead and used the Tesla UMC. A full charge from 12% was predicted to take 25 hours. Good thing I wasn’t in a hurry to leave!
The next day after a reasonable nights sleep I realised that in my haste the previous night to start charging, that there were actually multiple 15A outlets installed to power the larger dryers in the Laundromat. I was then able to swap out the 10A lead, for the 15A extension lead I’d brought just in case and was able to cut my charging time by 30% using the 15A tail on the Tesla UMC. In the end I was fully charged and ready to go 7 hours earlier than I’d originally expected.
Oopsie at 10pm
The problem with a 24-hour Laundromat as a charging point is that sometimes people want to use the machines. What I didn’t realise is that there were only a handful of 15A outlets and hence when I “borrowed” one for 16 hours, there was always a chance someone would come along, need to use the Dryer and then unplug my car.
My Tesla notified me of an interruption to the charging at about 10pm on the second night. I went downstairs and found the cable had been unplugged and the dryer was drying someones clothes just happily. I quickly reconnected it to the adjacent outlet and we were back charging again. No harm, no foul.
Around Town
We were in Monto. Population 1,200 people. There are ZERO Electric Cars in town and most EVs never trek the highway since there are no charging points between Kingaroy and Biloela. So driving the Tesla turned a LOT of heads around town and when I was pulled over outside of Gayndah by the police for a roadside Random Breath Test (RBT) the officer commented he’d never pulled over a Tesla before.
When in Monto one of the locals was asking about the car, calling it a “City Electricity Car” which sounded so weird to my ears, but I’ve since been calling the Tesla “My Electricity Car”. I meant, it kinda is…
Of course there were other travellers from afar that knew what a Tesla was and some kids at Cania Gorge car park did some poses and a dance for SentryCam that was hilarious, so that was cute. I digress…
Side Trip
There’s some interesting things to see in and around Monto, but the most popular place to visit is a 20 minute drive North of town. The Cania Gorge is a rugged but beautiful sandstone gorge carved out by Three Moon Creek over thousands of year and has lots of lookouts, small caves and hanging rocks as well as an abandoned Gold Mine.
We decided to make the trek on Saturday morning and took Tessie up to the Cania Dam, then worked our way back to town stopping at the primary bushwalking hotspot. We were bushwalking for about an hour and a half and saw some inspiring scenery. Well worth the look!

The Drive Back
After a recommendation from the publicans, we were determined to drive an extra 6 kilometres, though it took an extra 18 minutes, to go back via Goomeri, and stopped at the The Goomeri Bakery to grab brunch. There was a strong headwind in the morning so as an extra insurance policy we drove for 200 kilometers (125mi) at 90kph (56mph) then realised we’d reach Gympie with 20% charge which was more than enough.
The rest of the trip was uneventful after a quick 45% charge at the Supercharger we made it home with plenty of range to spare.
The Statistics
There are so many variables that go into range I’m not going to cover those here. To be honest we’re looking at those we can control: starting charge level, running the Heating/Air Conditioning, using the Aero-Wheel covers, tyres inflated to the correct pressure, driving with Chill Mode enabled just choosing to drive as smoothly as possible and for one leg as mentioned, driving at 10kph below the speed limit.
What I can’t control are things like headwind, external temperature and elevation changes. Taking much the same road means this trip can provide many leg by leg averages I can hopefully extrapolate to better predict future trips. The elevation difference is 219m from Home to Monto, hence there’s a penalty on the outbound trip for sure and more care is needed in that regard.
Outbound trip:
- Home-ish –> Gympie 155Wh/km (107k) +33m Elevation
- Gympie –> Mundubbera 168Wh/km (201k) +106m Elevation
- Mundubbera –> Monto 169Wh/km (110k) +80m Elevation
- Weighted average: 163Wh/km
Homebound trip:
- Monto –> Goomeri 146Wh/km (248k/200k @90kph)
- Goomeri –> Gympie 132Wh/km (76k)
- Gympie –> Home 140Wh/km (119k)
- Weighted average: 140Wh/km
The homebound trip was marred by headwinds on the long first leg to Goomeri that, had I not travelled at 90kph, would have been much worse energy consumption, though it probably still would have been fine.
Outback Irritations
The Australian “Outback” is difficult to define as to where it starts and where it ends, and does it really matter anyway? Suffice it to say when you’re out on those highways where there’s limited mobile phone service it means that many of the features city-dwellers take for granted just don’t work once you’re away from major civilisation. Here are some realities that hit you.
AM Radio
For those that don’t know, the problem with AM Radio is that the variable speed drives, inverters and power electronics that comprise the drive train in an Electric Vehicle create a lot of broad-spectrum EM noise. Unfortunately a large amount of this is at lower frequencies across the AM Radio band to the point at which Tesla gave up trying to have an AM Radio in their cars. In Australia the outback is well covered by AM Radio stations even to this day, with ABC, Radio National and some commercial stations well catered for. Whether you like their content or not isn’t the point…Teslas need not apply.
FM Radio
Tesla have a “simple” and easy FM Radio interface where you have a “Favourites” list of Radio Stations you can build yourself, and a “Direct Tune” option. When you’re in range of cellular data (so far as I can tell) another option appears (it can not be summoned you just have to wait for it to appear) called “Stations” which is a list of FM stations that the Tesla believes it can find or that should be there based on your location.
Under Direct Tune there is no way to ‘Seek’ for an FM Station. Knowing a handful of FM Station frequencies along the road (thanks mostly to roadside billboard signage) we were able to tune directly to some stations and Favourite them for quick access, even when they didn’t appear in the Tesla generated “Stations” list (when it bothered to appear).
It would be better for the driver to decide what level of FM drop-out is acceptable rather than an algorithm in the Tesla. Adding a simple seek button like every other FM Radio I’ve ever used in a car, would be easy to implement. You press and hold for 2 seconds, the FM Radio seeks up or down the band until it finds a signal then pauses and waits for a few seconds. You then select that station and it stops there, or you don’t and it then keeps scanning until it finds something else. The FM Carrier threshold to be set to a reasonably faint level because I’d rather listen to choppy FM sometimes than silence.
I found myself searching the internet for radio station frequencies that might be listenable along that road and pre-entered them before we hit the road but honestly, that’s a horrible hack and this is exceptionally easy for Tesla to fix with a software update.
Satellite Radio
SiriusXM is regrettably not offered in Australia, despite the fact it does actually work in Australia. Tesla don’t offer it here on the basis that SiriusXM don’t offer it here which makes sense, so I don’t blame Tesla for that. Honestly it would be absolutely worth the money if you’re doing lots of outback travel in Australia to have a Satellite radio service. With the progression of Starlink there’s probably a superior option in Satellite internet, but that’s an expensive option and whilst some have rigged up a Starlink antenna inside their Model 3 in Australia already, it’s not exactly discrete or compact and not really convenient - at least not yet. Maybe someday…
TeslaMate Telemetry
I was really interested in pouring over the telemetry data from Tessie when I got home as I’d set up my own private TeslaMate VM in late 2021 after I bought my Tesla. I was partly surprised but partly not then I found data gaps between locations on the road trip that loosely aligned with my recollection of cellular coverage gaps. The extract below clearly shows those gaps in Telemetry Data.
Hence it’s clear that the Tesla data streaming API has a limited buffer and once you’ve been out of reception for a certain amount of time, the data falls off a cliff and dissolves into nothing, and it never makes it to the Cloud (and hence TeslaMate). Good to know.
Conclusion
Unsurprisingly this is first time since owning my Tesla that I’ve felt range concern. (Don’t call it Anxiety - I know what Anxiety feels like and this wasn’t that…)
That said it’s also the first time I’ve pushed the limits of my car in terms of range and it performed exceptionally well. I found that the Tesla trip graph wasn’t the best indicator and that the much liked A Better Route Planner was too pessimistic. That said it’s highly configurable and in terms of power consumption it can be adjusted. This trip has allowed me to tweak the Model 3 default in ABRP from 160Wh/km to 150Wh/km as its predictive default making future trip predictions more accurate.
Of course the whole trip could have been much less stressful with a few DC Fast Chargers installed at mid-points on the trip. There are plenty of reasonably sized towns on that road: Goomeri, Mundubbera, Eidsvold for example. That’s simply a matter of time. The QESH (Queensland Electric Super Highway) Phase 3 is currently under construction but none of their chargers are destined for the Burnett Highway.
Some councils are taking it into their own hands with partnerships with industry like the new Kingaroy charger for example. More destination chargers will eventually start appearing making trips on the Burnett easier for overnighters or even part-day trippers, but for me at least one thing is for sure: touring in the Model 3 was very comfortable, very relaxing and now I know I can make those legs without too much difficulty - I’m more confident in trips like that again in the future.
Tesla User Interface
I’ve written about my new Model 3, but wanted to pull together some thoughts about the Tesla User Interface (if I can call knobs, buttons, switches and a screen in a car a User Interface…pardon my Engineering parlance…) now that I’ve driven my Tesla for nearly 8,000ks (5,000mi) over the past 4 months.
V10 to V11
The changes made between V10 and V11 I’ll cover off in future maybe in another article. Most of the changes haven’t been improvements overall and I’ll cover those changes that are specifically detrimental below. Suffice it to say, most users/drivers didn’t like the V11 upgrade very much. For me, I’d only spent two months using V10 so re-learning where most things were wasn’t a big change for me. Others that had been using their V10 interface for years…were much more annoyed and I can understand why.
Easy Access Is Subjective
Having designed HMI Screens for two decades in critical plant control systems, my view on what information is critical vs what information is nice-to-have is very different from most people it’s fair to say. I’ve read so many peoples opinions about whether tap-tap-swipe to get to a function or not is just too hard and if glanceable information is missing. Frankly it’s opinionated and most people are too influenced by their own biases to be objective and to be honest with themselves.
Before we tackle that, let’s think about Tesla’s perspective, because it makes a big difference in understanding some of their choices.
Tesla: We expect you to be using AutoPilot
Not all the time, but most of the time. Yes, it’s true that AutoPilot on city streets is a bad idea - too many variables, obstacles, disjointed lines and things to account for but it’s getting better every month. On the highway or freeway it’s pretty solid and reliable.
In a non-touchscreen vehicle people can use tactile feel and use spatial awareness to locate the buttons, knobs and switches without taking their eyes off the road. Of course in recent years many vehicles have introduced touchscreens with CarPlay/Android Auto or their own entertainment system, as well as voice controls on some mid/high-end models. Whilst Smartphones have taken most of the blame in recent years for driver inattention there’s no denying that touchscreen entertainment consoles in cars also play a role in driver distraction. One might wonder if it’s safe to have any screens in a vehicle without Auto-lane Keep Assist (or whatever name you like) in the vehicle as well, but I digress.
For this discussion we’ll exclude the entertainment system-like functionality as it’s clearly a heavier touch than other interactions. For that matter we should define the four categories for functionality:
- Glanceable Information: The driver averts their eyes from the road briefly to quickly locate a key piece of information then returns to watching the road in between 1 to 2 seconds
- Glanceless Controls: The driver is able to activate a control or function without taking their eyes off the road
- Light Touch Controls: The driver averts their eyes from the road briefly to locate and activate a control or function then returns to watching the road in between 2 to 5 seconds
- Heavy Touch Controls: The driver averts their eyes from the road to locate and activate a complex control or complex function then returns to watching the road in between 5 to 15 seconds
Let’s look at examples of each below, in no order of priority of preference.
Glanceable Information
- Speed
- Indicator (Left/Right/Hazard) Status
- Headlight State
- Fuel/Charge Level
I’m excluding non-automatic, and non-electric vehicle items like Oil Temperature, Oil Pressure, Engine Warning, tachometer and so on. Also worth noting that some items like Windscreen wiper state is directly observable without any indication on a dashboard, hence that’s excluded as well.
About Binnacles
In non-Tesla vehicles this information is almost always located in a Binnacle or Instrument Cluster if you prefer. It’s directly behind the steering wheel only requiring the driver to drop their gaze and look through a hole in the steering wheel. This isn’t perfect either since we can’t glance through the wheel at certain points of wheel rotation (when turning) and not all cars have good tilt/telescope and/or seat height/depth adjustment to suit every person. Due to my height in some cars I’ve driven, there’s simply no physical way to adjust the steering column and seat so I can see all of the Binnacle. The top is sometimes obscured and I’ve had to duck my head forward and down slightly to read the speedometer particularly at higher speeds.
An alternative to a Binnacle is a heads-up display, which super-imposes information that only the driver can see, on the windscreen directly in front of them. I drove a Prius-V for a few years that had this and I really loved it, however having something in your direct line of sight is not always ideal. Given the costs of implementing HUDs have dropped these remain an attractive alternative to a Binnacle that serve much the same function.
In a Model S and X there is a Binnacle, but on the 3 and Y there isn’t and no Teslas have HUDs. I have yet to find a seating position or steering wheel angle where the screen is obscured from view, but this visually clear sightline is offset by requiring not just a dip of vision, but also a glance to the side towards the center of the vehicle. Ultimately this takes slightly longer but in normal use isn’t much of an additional safely concern and with AutoPilot running, it’s no concern at all.
Glanceless Controls
- Indicate Left/Right
- Headlights High/Low Beam
- Windscreen Wipers (Once/On/Speed Controls)
- Drive Mode (Forward/Reverse/Park)
- Cruise Control (Activate/Set/Resume/Increase/Decrease)
- Sound System Volume (Skip/Pause/Stop Playback)
- Steering
- Accelerating/Braking
- Honking the horn…
Light Touch Controls
- Air-conditioning settings (Temperature, Fan, Recycled Air, Demisting)
- Door Locks (Individual/Group)
- Seat Heating
- Radio / Music / Stereo basic changes
- Report Issue / Dashcam Record clip
- Navigating to a Favourite / Calendar location
Heavy Touch Controls
- Sound system setting adjustments
- Navigation to a specific location requiring search
- Pretty much everything that isn’t required explicitly for driving
To be fair there’s very little good reason for messing with heavy touch controls when you’re driving, even with AutoPilot. The risk is just too great. Some items require the car to be stopped to adjust and parked with the Park Brake applied for others - which feels like the right call. I don’t believe there are any truly heavy-touch control items of concern in the current Tesla UI.
Why AutoSteer is so Important
#RantBegins
Auto Lane-Keep Assist or AutoPilot/AutoSteer functionality is very important due to gaze-affected steering. There have been studies that look into the correlation of gaze and eye-position and induced movement of the steering wheel. In other words - we tend to steer in the direction we’re looking. The longer we look away from in front of us, the more we will drift in the direction we’re looking.
Before LKA/AP-AS was possible the only option was to ensure controls were tactile and binnacles were clear and concise to minimise this. With LKA/AP-AS technology, this is less of an issue provided it’s actually able to be used and is in use. The alternative position to think about though is, if AutoPilot isn’t working (poor conditions, dirty cameras/sensors) or disabled by the driver, then the only means to accessing information will then become standard tactile controls and a binnacle.
If we suppose AutoPilot isn’t always in use, the lack of a Binnacle and minimal tactile controls should result in a higher incidence of accidents with Tesla vehicles, particularly Model 3 and Y and yet there is not. Beyond the possibility that these are non-issues (could be…) a possible reason for this is that the higher cost of entry for these vehicles precludes ownership/access to younger drivers. It has been shown conclusively that younger drivers do not handle distraction as well as more experienced drivers. Therefore the marginally higher risk in non-AutoPilot situations is likely offset by the older driver demographic.
Projecting forward in time from here requires a lot of faith and assumption. If we assume that AutoPilot improves to the point where it can drive as well as or better than a human in all situations, then the interface deficiencies become a non-issue. Maybe even get rid of the Steering Wheel and the stalks? Hmm. The problem is that in that extreme scenario AutoPilot then becomes a requirement to use the vehicle in which case it is forced always on and the car can not move without it. Many people will never choose that option, therefore some balance needs to be found between full autonomy and catering for human attention to the road under non-AutoPilot operation.
#RantOver
Where Tesla’s Interface Falls Short
Much of the complaining for users is more centered around Heavy Touch controls or items that don’t directly affect safety or driveability or common usability of the vehicle. That said there are a few exceptions that fall under Glanceless Controls and Light Touch Controls that aren’t often covered that are currently not ideal:
Headlights: In every other vehicle I’ve driven, I can turn on and off headlights, set low and high beam and auto-highbeam (where fitted) using the stalk. In the Model 3 you can only turn lights off (if the Tesla decides they should be on in the first place) by using the touchscreen. Pulling the left stalk towards you flashes High Beam, whereas pushing it away from you and releasing toggles between Low and High Beam.
Headlight Suggestions: Pulling the left stalk towards you is common in many cars for flashing High Beams so should be retained, but add Pull and Hold for 2 seconds to toggle between High and Low Beam. Pushing forwards on the left stalk toward could toggle Auto-highbeam on and off, and Push forwards and Hold for 2 seconds could toggle the headlights on and off. Note: Normal cars don’t try to overload all of this functionality into two switch actions, they employ turn-dial positions and switches specifically for each independent control for a reason.
Wipers: Currently the end button on the left stalk has two depressed depths: Shallow preforms a single wipe, full depth performs a cleaning spray and wipe function. There is no way of changing the speed or cycle via the stalk, though pressing the button at all brings up a pop-up on the Touchscreen, this now becomes a Light Touch control for something you don’t want to be taking your eyes off the road in heavy rain conditions. It might be fine if the auto-wipers worked reliably but they don’t and given this impacts driver visibility it’s very important.
Wipers Suggestions: A single shallow press and release could cycle between OFF->Intermittent Slow->Int Fast->Continuous Slow->Cont Fast->OFF. A full depth press could single wipe with a full depth press and Hold for 2 seconds to trigger a cleaning wipe.
Demisting: In V10 demisting controls weren’t associated with a stalk, but rather on the bottom edge of the Touchscreen, easily available if needed. Considering the urgency or not employing these as they affect driver visibility it is very odd they were removed from the bottom bar in V11.
Demisting Suggestion: Put the controls permanently on the bottom bar for quick access.
Non-retentive Assumptions
If I could put my finger on one gripe about Tesla’s UI…it’s that many functions and settings are non-retentive. When you stop the car and get out, then get back in and drive off again later they reset to the factory defaults. There is no retention of my previous settings. Headlight for example…stop assuming that the light level outside require headlights. If I want to turn them off, when I do, they should stay in that state until I turn them on again.
Not-So-Auto
Nothing is perfect, but when things are designed to work in an Automatic mode, that mode needs to work in a pattern that is discernible, consistent and relatively well otherwise people can’t/won’t use it.
- Auto-Highbeam: It does not detect on-coming vehicles very well, particularly on bends. Hence when a human would pre-dip their headlights seeing an on-coming vehicle in the distance, the Tesla will leave them on high beam until it’s effectively head-on. Not good.
- Auto-Wipers: We had a wet summer and I had many, many opportunities to observe the behaviour of the wipers. I liken it to game of drip-chicken. How many drips need to accumulate on the windscreen before the automatic wipe wipes them away…and will it do so before it becomes a safety hazard for bad forward visibility for the driver? It’s almost fun, if it wasn’t dangerous. I often lose this game of chicken as I have to tap with single wipe several times to avoid an accident through poor visibility before the auto-wipe wakes up and does something autonomously.
- Auto-Steer Speed Limiting: This one might sound needy but it’s simple: When in full AutoPilot, the Tesla attempts to read the speed sign and when the Tesla passes in-line with that sign, it will automatically adjust the speed limit up (if it was set higher as it’s Max set-speed previously in the drive) or down accordingly. Going up is fine, but going down isn’t, since it only drops your speed once you’ve passed the sign, meaning that until the cruise-control lag slows the car down you’ve been speeding for a hundred meters or so when you’re dropping from 100 to 80 kph for example. The fix is simple - it’s basic physics. You have depth perception (and a GPS) in a Tesla so you could calculate the distance between the current position and the upcoming speed sign change position, so figure out based on the deceleration curve when to start slowing down so you reach the speed limit when you actually pass the sign. In Australia the police will intentionally set up speed traps in those spots trying to catch drivers out…it’s a speeding ticket waiting to happen.
- Emergency Lane Departure Avoidance: I have had this try to auto-steer me back into my current lane on a three-lane divided freeway when I was just changing lanes. Clearly the system thought I was drifting out of my lane because I wasn’t changing lanes quickly enough, but wrestling with the wheel at 100 kph is pretty scary - literally fighting with the car. Goodness knows what the other drivers behind me thought was going on!
- Mirror Auto-Dim: I’m used to being able to dim my rear-view mirror manually, using the tried-and-true manual prism toggle lever. These days though auto-matic is the rage and now we apply an electro-chromatic coat which turns darker when a voltage is applied to it. Tesla’s can automatically dim the side and rear view mirrors when it determines that it’s dark enough outside. How about a manual switch? Can I please dim my mirrors when I want to? I’ve found myself avoiding looking in the mirrors at Twilight because of this and relying on the cameras instead. Not safe or ideal.
Conclusion
If we accept the addition of AutoPilot features easily offsets the marginal increase in delay for glanceable information then this is a tradeoff worth making for an otherwise unobstructed view of that information. The controls on the steering column (left and right hand stalks and thumb control wheels/joysticks) satisfy most of the key requirements for glanceless controls. They fall short however on: wiper speed control and headlight control and I suspect this is due to over-confidence by Tesla in their automatic headlight and automatic wiper controls.
Why Change Tesla, why? I’ve been thinking about what would/could motivate Tesla to modify their User Interface and thinking specifically about the Demisting features. One of the temptations would be to use end user real-world data to draw conclusions about the use regularity of certain features. If so I can absolutely understand how something like the demister button would be moved. In the real world, most people would rarely use this as the conditions need to be right for it to be required. The problem with that though is the thinking behind a big Red Button emergency stop. Sure we don’t push the big red button often, but it’s there in case you need it in a hurry - which is when you’ll REALLY, REALLY want to use it! Quick access therefore can not only be reserved for items of high regularity but to reduce the high risk of unwanted outcomes.
Of course I have no evidence that this is what Tesla have done or is doing, but if not I struggle with the thinking behind some of the V10 to V11 changes. Beyond this I think there’s a hard limit as to how many more functions could or should be pushed off physical controls and on to a touch screen provided the intention is to have a human driver in control of the vehicle AT ANY POINT. One user interface can serve both purposes but a little bit of tactile controls makes it safer in both use cases.
All of that said, the only good thing is that unlike most other car manufacturers, a fix to many of the above is only a software update away.